Method Overview
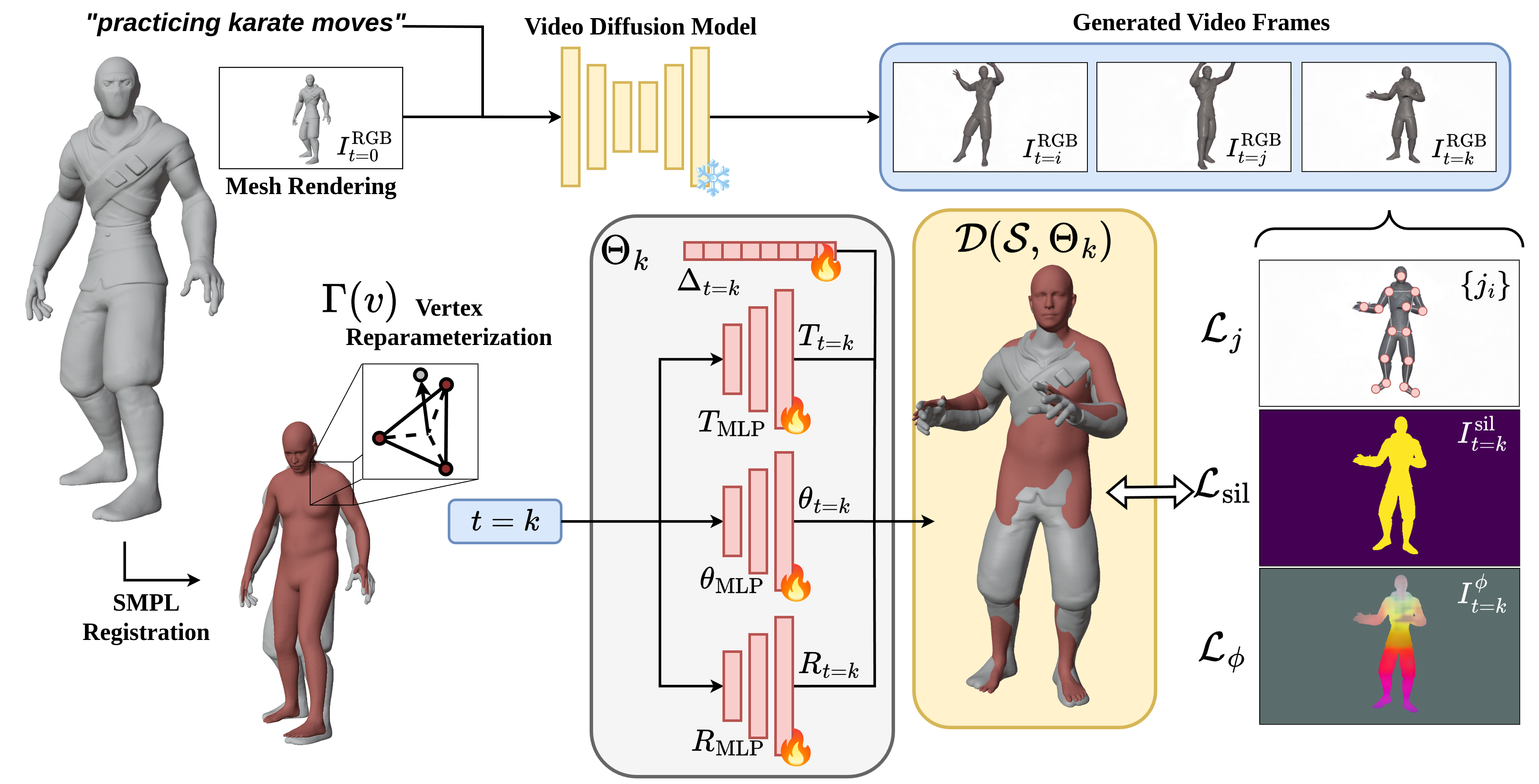
We present a novel approach for text-driven animation of 3D humanoid meshes.
- Given a static 3D humanoid mesh and a text prompt, we generate a motion video using a Video Diffusion Model (VDM) conditioned on the rendering of the mesh from a single view.
- To animate the input mesh, we use the SMPL body model as a deformation proxy. This involves: 1) Fitting the SMPL model to the input mesh, and 2) Anchoring mesh vertices with SMPL faces.
- Finally, we optimize for the neural parameters to track the motion from the video using body landmarks, silhouette mask and DINOv2 dense features.