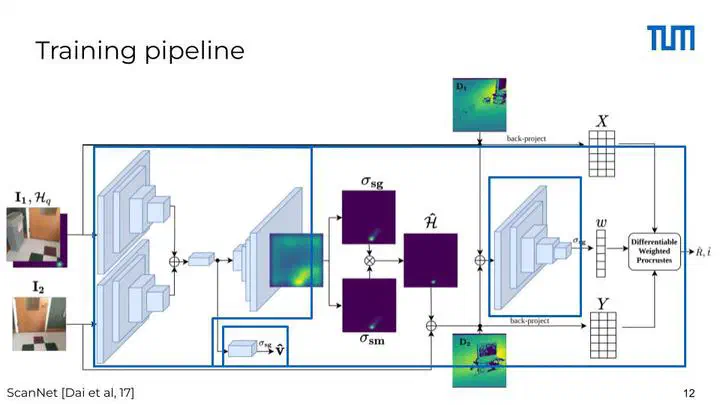
We present an end-to-end learnable, differentiable method for pairwise relative pose registration of RGB-D frames. Our method is robust to big camera motions thanks to a self-supervised weighting of the predicted correspondences between the frames. Given a pair of frames, our method estimates matches of points and their visibility score. A self-supervised model predicts a confidence weight for visible matches. Finally, visible matches and their weight are fed into a differentiable weighted Procrustes aligner which estimates the rigid transformation between the input frames.
Marc Benedí San Millán
PhD Candidate @ Visual Computing Group
My research interests include Computer Vision, Computer Graphics and Deep Learning.