Learning Robust Correspondences Estimation
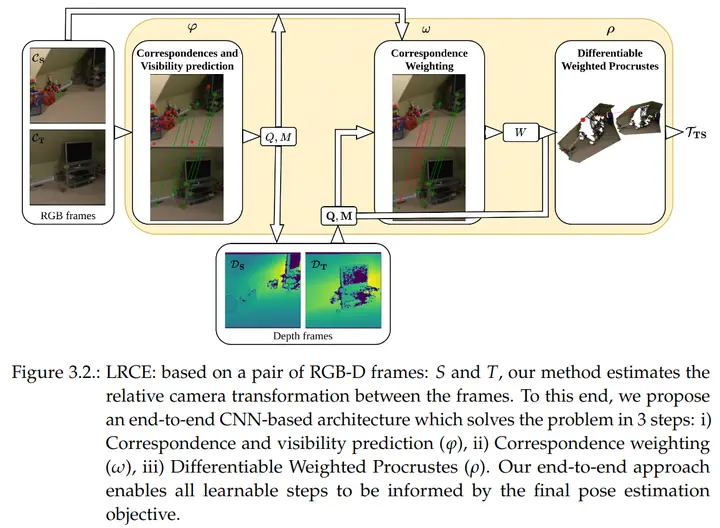
LRCE addresses the challenging problem of relative camera pose estimation in computer vision, essential for applications like 3D reconstruction, Structure from Motion (SfM), and Simultaneous Localization and Mapping (SLAM). Estimating a camera’s position and orientation from a sequence of images has been a long-standing issue in the field.
Main Contributions
LRCE introduces an end-to-end differentiable model for pose estimation between pairs of RGB-D frames (color + depth). The key idea is learning confidence scores for correspondences (matched points between images) in a self-supervised manner, helping to filter outliers and improve pose accuracy.
Key Components:
- Correspondence and Visibility Estimation: Predicts matching points between two frames and their visibility.
- Correspondence Weighting: Assigns confidence scores to filter unreliable correspondences.
- Differentiable Weighted Procrustes: Optimizes the final pose estimation by aligning the points using their confidence scores.
Evaluation
LRCE was tested on the ScanNet dataset, showing improved performance in matching and pose estimation compared to traditional methods (e.g., SIFT, ORB) and modern deep learning techniques (e.g., LoFTR). Its differentiable, self-supervised nature makes it particularly robust in wide-baseline and occlusion-heavy scenarios.
Conclusion
This thesis demonstrates how integrating end-to-end learning and self-supervised weighting can make camera pose estimation more accurate and robust. The source code is publicly available for further research and improvements.
Marc Benedí San Millán
PhD Candidate @ Visual Computing Group
My research interests include Computer Vision, Computer Graphics and Deep Learning.