Using VSCode in Slurm

TL;DR: Stop running VSCode’s
vscode-serveron the Slurm login node. Two recipes here move it into a real Slurm job so the editor lives on the compute node you actually allocated — meaning you can debug and run code on the GPU it gave you, and the login node stays free. Pick the easy one (code-serverin a browser) or the flexible one (per-jobsshdyou connect any IDE to, including PyCharm).
Table of Contents
Although I don’t use Visual Studio Code[1] as a code editor (I use Neovim[2] 🦸), many colleagues use it as their primary editor.
(The solution presented here also works for PyCharm[4]!)
The problem
To develop in our Slurm[3] cluster, users connect VSCode to the “login node”, which starts the vscode-server process there.
This is not a problem by itself, but when many users do it simultaneously, it starts to consume a lot of resources on a machine that should only be used to manage Slurm jobs.
Additionally, this setup only allows for editing the code, not for executing (or at least I hope they are not running code in the “Login node” 🤞) or even debugging.
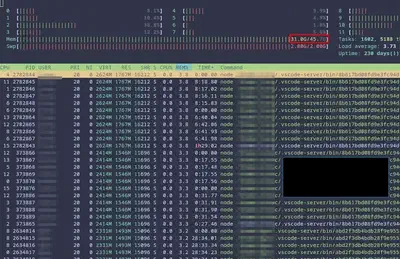
vscode-server processes from many users taking 30GB of memory!
Advantages
In the following sections, I will explain how to run VSCode inside Slurm[3].
This solves the problem of adding load to the login node. Additionally, since the code editor process will live inside a Slurm job, we will be able to debug and run code directly in the job. That’s very convenient!
🧑💻 The easy solution: VSCode on the web!
This solution is super simple to set up! It consists of running code-server[5] as a Slurm job and accessing it through the web browser.
First, we need to install the binary in our system. There are many options for that, so just pick up the most convenient for you. See the list of options here. In my case, I choose the Standalone release and put the binary in my path.
Second, grab the Slurm job file:
📥 Download code-server.job — adjust the #SBATCH lines (partition, time, GPUs, memory) to your cluster, then submit it with sbatch code-server.job.
The script picks a random free port, generates a strong password (openssl rand -base64 24), and starts code-server listening on that port with password auth.
⚠️ Security note. The job binds
code-serverto0.0.0.0, which means anyone on the cluster’s internal network can reach the port. The bundled password is randomly generated — don’t replace it with something weak like1234for real use, or someone who can probe ports on your node has an interactive shell as your user. If you can, bind to a specific internal interface instead of0.0.0.0, or front the service with SSH port-forwarding and bind to127.0.0.1:$PORT. Treat the password printed to the job log as a secret.
Finally, once the job has started, we can open the editor using any web browser and navigating to the IP of the node and the PORT.
That’s it!
If the node is not accessible from the Internet, use port-forwarding via SSH.
👷 The complex solution: Start your own sshd process
If you are up for a more complex solution or use other IDEs like PyCharm, you can use the next configuration. It involves starting sshd in a Slurm job and then connecting our IDEs to the new process (instead of the global sshd process).
Step 1: Create the SSH keys
Generate a dedicated key pair for this workflow (run this on the login node, or anywhere your $HOME is shared with the compute nodes):
ssh-keygen -t ed25519 -N "" -f ~/.ssh/slurm_sshd_key
This creates two files: ~/.ssh/slurm_sshd_key (private) and ~/.ssh/slurm_sshd_key.pub (public). The -N "" keeps the key passphrase-less so you can connect without an ssh-agent; if you’d rather have a passphrase, drop -N "" and have an agent loaded.
Step 2: Authorize the key
The sshd we’ll start in the Slurm job will check ~/.ssh/authorized_keys on the compute node. Add the public key there:
cat ~/.ssh/slurm_sshd_key.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
This step assumes your home directory is shared across the login node and all compute nodes (NFS or similar). If it isn’t, you’ll need to repeat it on each compute node — or, better, fix the home-directory setup first.
Step 3: sshd Slurm job
Grab the Slurm job file:
📥 Download sshd.job — adjust the #SBATCH lines for your cluster and submit it with sbatch sshd.job.
The script picks a random free port and starts sshd -D in the foreground using the host key you generated in Step 1. Note the -f /dev/null (no config file): on some modern OpenSSH builds you may need to point -f at a minimal sshd_config instead if it refuses to start with no defaults loaded.
Step 4: Test the connection
At this point, you should be able to connect using ssh to the Slurm job.
ssh user@node -p <PORT where the server started> -i ~/.ssh/slurm_sshd_key
Notice that the ssh session can only see the resources allocated to the job (for example the gpus).
Step 5: Connect your IDE
Finally, use your IDEs “Remote Connection” feature to connect to the job.
Step 6: Remember to end the sshd process
It is important to cancel the Slurm job when we don’t need the sshd listening anymore.
📑 References
[1]: https://code.visualstudio.com/
[2]: https://www.lunarvim.org/
[3]: https://slurm.schedmd.com/
[4]: https://www.jetbrains.com/help/pycharm/getting-started.html
Marc Benedí San Millán
PhD Candidate @ Visual Computing Group
My research interests include Computer Vision, Computer Graphics and Deep Learning.